
ALF
The ISIS Neutron and Muon Source has a suite of over 30 specialised neutron and muon instruments that enable materials to be studied at the atomic and molecular level.
View the interactive instrument map below ⇩
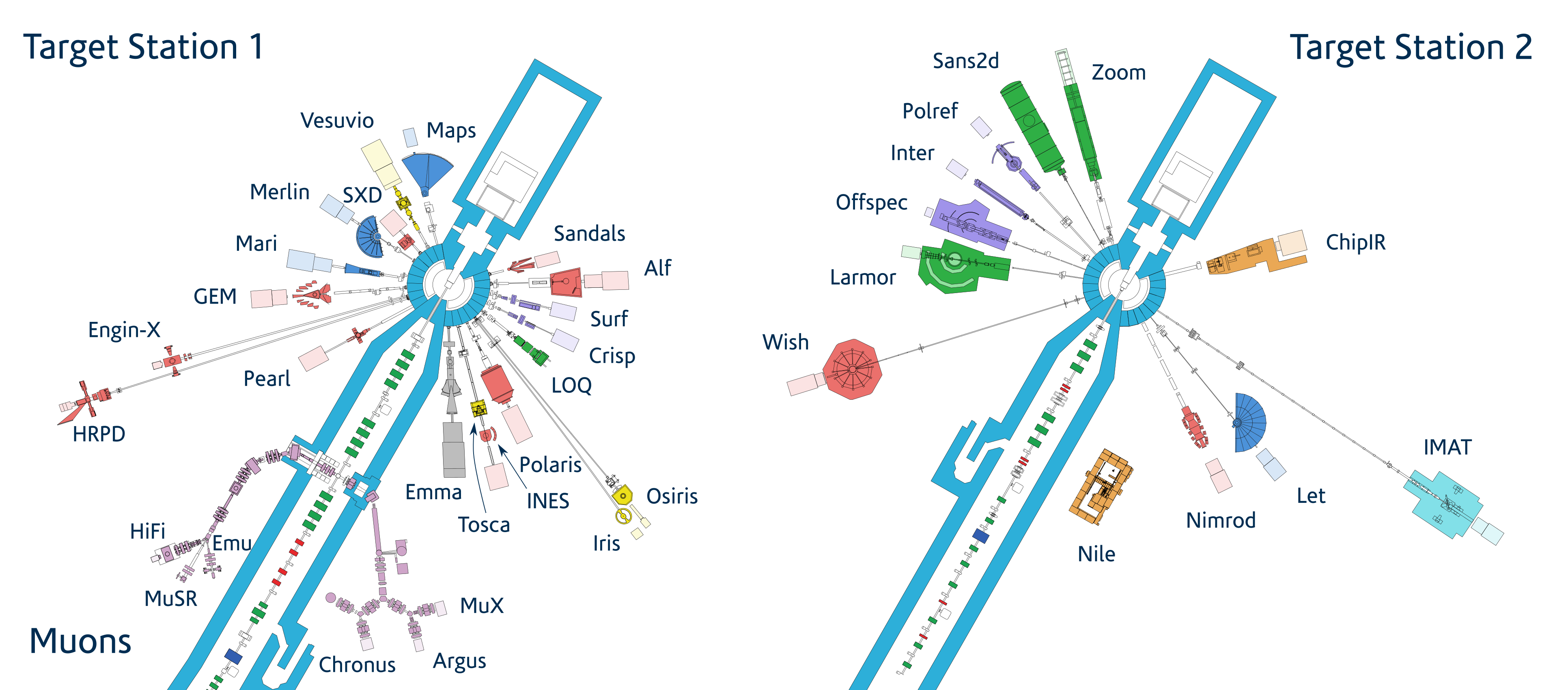
The instruments available at ISIS facilitate a range of techniques, each with different merits.
At ISIS we strive to lead the way in the innovative development and exploitation of neutron and muon sources, science, instrumentation and technology. We have lots of new additions and upgrades planned to keep us at the cutting edge of scientific discovery.
